Is anybody still experience similar crashes. I think my openhab installation in Docker does behave similarly and maybe I’m able to help with debugging the issue. Currently my openhab container starts using more and more memory over time and I cannot see any reason why it should:

My Install is still unstable.
I am not tracking memory usage but swap usage was high.

the CPU spikes are reboots of openhab

quick update,
I have decreased the workload on the Raspberry pi. its not the load on it.
I am going to try turning mqtt off. that seems to be the thing that crashes the system.
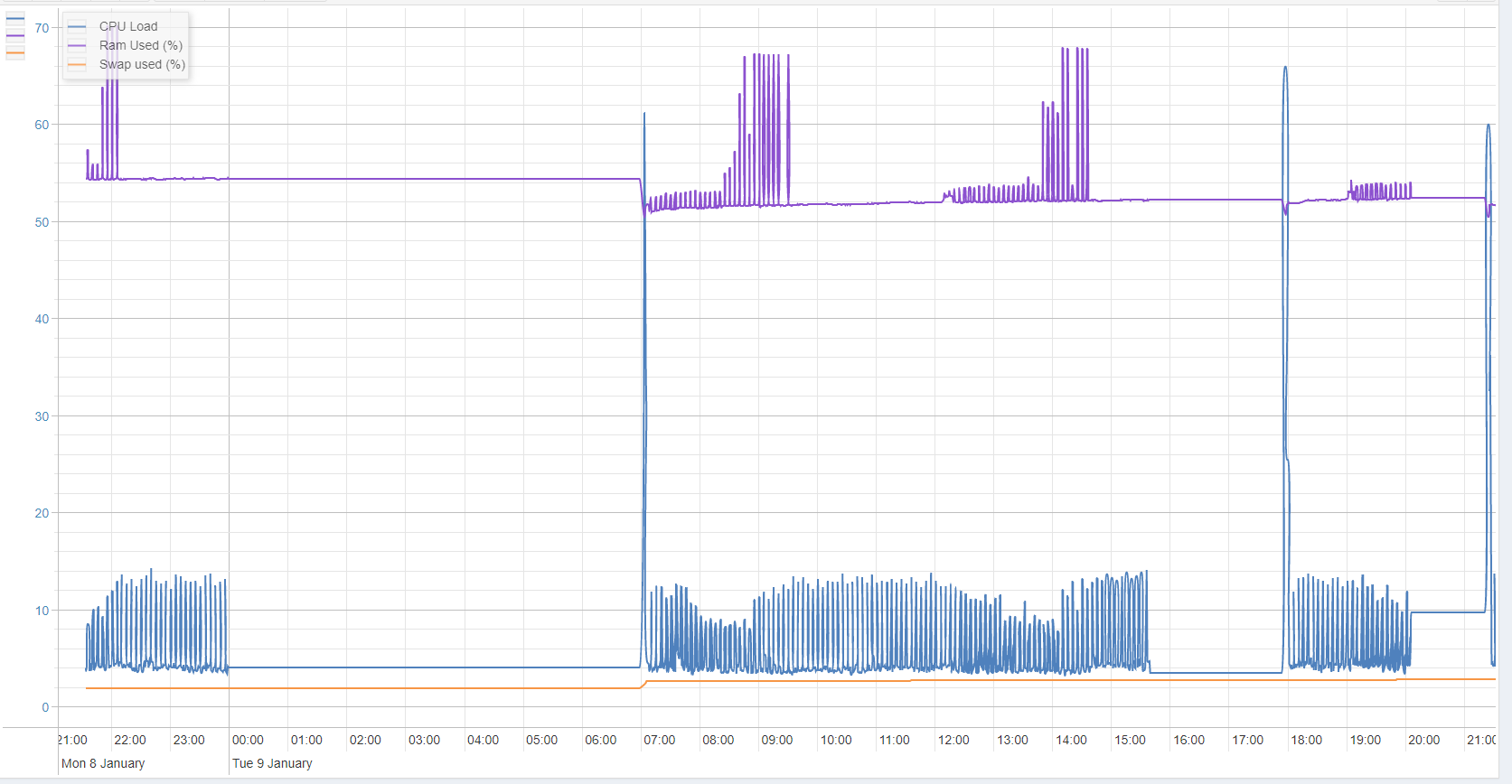
the usage is the same.
edit: i have turned down the rate that the sensor update lets see if that makes a diverence. my motion sensor wat trigger happy every 5 sec.
Mine’s crashing a lot too with a lot of memory usage being a cause or symptom and no warnings or errors in the (default) log.
## Release = Raspbian GNU/Linux 8 (jessie)
## Kernel = Linux 4.9.35-v7+
## Platform = Raspberry Pi 3 Model B Rev 1.2
## Uptime = 64 day(s). 21:33:24
## CPU Usage = 25.25 % avg over 4 cpu(s) (4 core(s) x 1 socket(s))
## CPU Load = 1m: 1.03, 5m: 0.95, 15m: 0.97
## Memory = Free: 0.07GB (7%), Used: 0.87GB (93%), Total: 0.94GB
## Swap = Free: 0.09GB (93%), Used: 0.00GB (7%), Total: 0.09GB
## Root = Free: 10.00GB (74%), Used: 3.40GB (26%), Total: 14.14GB
What can I do to help?
What are the bindings your using?
And is openhab the only thing on the server
This seems very strange issue - since top of the stack contains some Karaf related entries which are not there unless some “runtime update” is made.
r0 = 0xac25cc88
0xac25cc88 is an oop
org.apache.karaf.features.internal.resolver.CapabilityImpl
- klass: 'org/apache/karaf/features/internal/resolver/CapabilityImpl'
r1 = 0xa493aab8
Are you sure these are not caused by feature auto update or something like that? In general Karaf does not pull new snapshots alone unless there is explicit update request. From what I remember OpenHab was triggering this periodically.
Cheers,
Lukasz
Bindings:
mqtt1,kodi,chromecast,homematic,astro,rfxcom,weatherunderground,systeminfo,hue,expire1,unifi
OpenHAB is the only thing running apart from Mosquito.
did you notice anything before the crashes.
like spikes in ram or cpu?
I didn’t but I wasn’t looking.
It did it again. The was an increase in CPU load (memory load was constant at 50% and then the thing just stopped (just after 20.51) until I restarted it at 22.40).
See graph (green is memory used % and blue is CPU load).
 .
.
Logging just stops at 20:51.
Perhaps this is just a hardware fault that has developed with my RPI?
I removed the Unifi binding and did a clean install and then a restore from my back -up and it seems okay now but:
Using the openHabian config tool to copy my files on to a USB stick didn’t work this time and I’ve no idea why - nothing worked so I had to repeat the fresh install.
Then finally MQTT didn’t work and I wasn’t able to uninstall and resinstall MQTT action as ithers have recommended as it wouldn’t uninstall so I re-installed Mosquitto again and rebooted and it worked.
It seems to be okay again but I’m really not sure I want to install the Unifi binding again in case it was that which causes the problems (unless it was a corrupt USB stick after too many writes).
The big problem I have it this seems to happen more regularly than I would like and getting it all working again should be easy but is never the same each time with different problems that need surmounting whose solutions involve spending hours going through forum threads to find answers that may, or may not work.
What’s the best current thread to enquire about the most reliable hardware solution to replace my Pi3 as it’s just not good enough for a home automation system?
I am running my system on a Rpi2b now i have made a clean install now and it has been running good for now i still need to see if it does in the couple of days. I have remade all my sitemaps and rules to be as efficient as possible. switched to inlfuxdb instead of MySQL.
all the errors that i had are gone the response time is way better. i will keep updating. i am planning on doing some tests with vm’s and running the same cofig in them but with diverend specs and simulated hardware.
I’ve ordered a SSD today which hopefully will remove that feeling that when something goes wrong that one wonders whether is a SD card or USB drive failing.
I suppose getting a spare PI and installing new bindings or upgrades on that first may also be the way to go.
A while ago I had similar symptoms - disk intensive applications were getting hiccups, over time PI was becoming irresponsible. At the beginning once a week, then once every three days. I initially thought it is wifi issue in my utilities room. Before I realised whats going on sd card died, I’ve lost few months of data stored in influx (yes I did run influx on sd card!) and I had to do a fresh installation.
Your situation seems to be slightly different since you was able to reinstall system, but please pay attention how often Pi hangs. If you see that it happens more regularly without any major changes to environment - it might be related to storage.
I’m expirencing similar issues as described in the initial post by @stefan13: openHAB 2.2 is crashing silently without exceptions or any useful entries in the logs. Meanwhile, I’m aware of three ways to trigger the issue, see below …
Is it solved in the meantime? Have you found a way to work around it? Have I missed something 
Anyway, I’m going to post here some information about my setup hoping to help finding similarities to others having the same issue.
System
OpenHABian-script applied to stock Debian9 on a
x86 based embedded system, 4GB ram, m-sata ssd (https://www.pcengines.ch/apu2c4.htm)
The system is dedicated to openHAB. Just openHAB, influx, grafana is running on it. No further services…
# uname -a
SMP Debian 4.9.65-3+deb9u1 (2017-12-23) x86_64 GNU/Linux
# java -version
java version "1.8.0_151"
Java(TM) SE Runtime Environment (build 1.8.0_151-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.151-b12, mixed mode)
Openhab is 2.2-release.
USB dongles for the RF-based bindings are connected via ser2net/socat to a RPi putting them in a better rf position. Ethernet is wired to the remote Pi (no wifi).
Used bindings
openhab> bundle:list | grep Binding
111 │ Active │ 80 │ 0.10.0.b1 │ Eclipse SmartHome AutoUpdate Binding
112 │ Active │ 80 │ 0.10.0.b1 │ Eclipse SmartHome Core Binding XML
209 │ Active │ 80 │ 0.10.0.b1 │ Astro Binding
210 │ Active │ 80 │ 0.10.0.b1 │ Eclipse SmartHome hue Binding
211 │ Active │ 80 │ 0.10.0.b1 │ Sonos Binding
225 │ Active │ 80 │ 2.2.0 │ Exec Binding
226 │ Active │ 80 │ 1.11.0 │ openHAB Expire Binding
227 │ Active │ 80 │ 1.11.0 │ openHAB FritzboxTr064 Binding
228 │ Active │ 80 │ 2.2.0 │ HarmonyHub Binding
229 │ Active │ 80 │ 2.2.0 │ Network Binding
230 │ Active │ 80 │ 1.11.0 │ openHAB NetworkUpsTools Binding
231 │ Active │ 80 │ 2.2.0 │ Rfxcom Binding
232 │ Active │ 80 │ 2.2.0 │ Systeminfo Binding
234 │ Active │ 80 │ 2.2.0 │ ZWave Binding
248 │ Active │ 80 │ 1.11.0 │ openHAB KNX Binding
249 │ Active │ 80 │ 2.3.0.201801190819 │ ZigBee Binding
Persistence
influxdb and mapdb
Three ways to trigger a “silent” crash
During the work with openHAB 2.2 I came across three situations, where openHAB died (restarted) without any notice in the openhab.log:
- Write out a modified .things file for example for RFXCom (rfxcom.things)
There’s nothing special in, see:
Bridge rfxcom:bridge:rfx1 [ serialPort="/dev/rfxcom", disableDiscovery=true] {
Thing rain RainOregon [ deviceId="36352", subType="PCR800" ]
Thing temperaturerain RainAlecto [ deviceId="61441", subType="WS1200" ]
Thing temperaturehumidity THKindZi [ deviceId="37122", subType="THGN122/123" ]
Thing temperaturehumidity THSchlaZi [ deviceId="1284", subType="THGN122/123" ]
Thing temperaturehumidity THDachSt [ deviceId="56068", subType="THGN122/123" ]
Thing temperaturehumidity THKuehlschrank [ deviceId="65028", subType="THGN132" ]
Thing temperaturehumidity THBuero [ deviceId="65284", subType="THGN132" ]
Thing temperaturehumidity THBadOG [ deviceId="60930", subType="THGN132" ]
}
- Restart one of the RF-based bindings (zwave, zigbee, rfxcom) through Karaf-console
openhab> bundle:restart <id>
Sometimes this was required to re-establish a socat-connection towards a remote RPi serving as ser2net.
In about one out of three times to restart a bundle, openhab crashed silently
- restarting openhab via systemctl
Sure, this will restart openhab , But, when using
/# systemctl restart openhab2.service
to restart the openhab service, openhab will start as usual, loads the models, initialize things, starts updating items.
But then, after 3 to 5 minutes, the silent crash is occuring leading to a (sometimes infinite) restart loop.
To break this loop, I had to:
/# systemctl stop openhab2.service
(.... wait few minutes ....)
/# systemctl start openhab2.service
If I do not touch the system, it is running stable for many days (weeks?). Rules are working, persistence is doing fine…
Since Martin @martinvw is suspecting the JVM probably causing this, how to isolate or to mitigate this?
Any thoughts?
Meanwhile I’ve updated JVM as suggested by @martinvw.
It’s now
# java -version
java version "1.8.0_161"
Java(TM) SE Runtime Environment (build 1.8.0_161-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.161-b12, mixed mode)
… behaviour is the same. Right after just writing the (unchanged) rfxcom.things file (content see above post), openhab crashes immediately. Next messages in the log are the startup messages:
2018-02-01 09:12:27.475 [INFO ] [el.core.internal.ModelRepositoryImpl] - Refreshing model 'rfxcom.things'
==> /var/log/openhab2/events.log <==
2018-02-01 09:12:30.564 [hingStatusInfoChangedEvent] - 'rfxcom:bridge:rfx1' changed from ONLINE to OFFLINE
2018-02-01 09:12:30.566 [hingStatusInfoChangedEvent] - 'rfxcom:rain:rfx1:RainOregon' changed from ONLINE to OFFLINE (BRIDGE_OFFLINE)
2018-02-01 09:12:30.569 [hingStatusInfoChangedEvent] - 'rfxcom:temperaturerain:rfx1:RainAlecto' changed from ONLINE to OFFLINE (BRIDGE_OFFLINE)
2018-02-01 09:12:30.577 [hingStatusInfoChangedEvent] - 'rfxcom:temperaturehumidity:rfx1:THSchlaZi' changed from ONLINE to OFFLINE (BRIDGE_OFFLINE)
==> /var/log/openhab2/openhab.log <==
2018-02-01 09:13:16.181 [INFO ] [voicerss.internal.VoiceRSSTTSService] - Using VoiceRSS cache folder /var/lib/openhab2/voicerss/cache
2018-02-01 09:13:16.316 [INFO ] [er.internal.HomeBuilderDashboardTile] - Started Home Builder at /homebuilder
2018-02-01 09:13:18.457 [INFO ] [.core.internal.i18n.I18nProviderImpl] - Locale set to de_DE, Location set to null, Time zone set to Europe/Berlin
2018-02-01 09:13:21.398 [INFO ] [.dashboard.internal.DashboardService] - Started dashboard at http://192.168.xxx.xxx:8080
2018-02-01 09:13:21.409 [INFO ] [.dashboard.internal.DashboardService] - Started dashboard at https://192.168.xxx.xxx:8443
So even with 1.8.0_161 the issue persists.
Could you advice how to isolate the cause?
I too had rules that either didn’t operate or were delayed, and I think I’ve found the answer.
It appears that Open Java, Oracle Java and Zulu Java work differently.
I have a large system with many rules, a lot of which used Thread::sleep for periods up to several minutes. On both OH2.2 and OH2.3 Snapshot Build 1203 there seems to be a limit on the number of threads open and this is different depending on which Java is used. Once the Thread limit is reached rules are queued up and only work when a thread becomes free.
Zulu seems to allow the most threads, whereas Oracle Java has the least. Open Java seems to be somewhere in the middle.
This manifested itself as rule triggering being delayed and I experienced this on both my current Debian Stretch 64Bit on a PC as well as my previous Pi3 on Jessie.
I’m now rewriting all my many rules with timers instead of Thread::sleep which is making a lot of rules more complicated.
Hopefully this is the fix to my reliability problems, I’ll update this post if it isn’t
FTR: I’ve just filed an issue regarding the silent crashes: